A ciência de dados (“data science” em inglês) é uma área interdisciplinar voltada para o estudo e a análise de dados, com o objetivo de extrair conhecimento para possíveis tomadas de decisão. Apesar de ter surgido na Academia, está cada vez mais presente no mundo dos negócios. A definição moderna de ciência de dados a define como a obtenção de conhecimento novo usando “big data” (se não for big, seria estatística) através de técnicas de mineração de dados (geralmente usando “machine learning”).
A mineração de dados (“data mining”) tem o objetivo mais ligado à automação de tarefas e infraestrutura de organização e acesso dos dados, geralmente em grandes quantidades, além de descobrir propriedades até então desconhecidas deles – algumas vezes, os profissionais dessa área são chamados de engenheiros/arquitetos de dados.
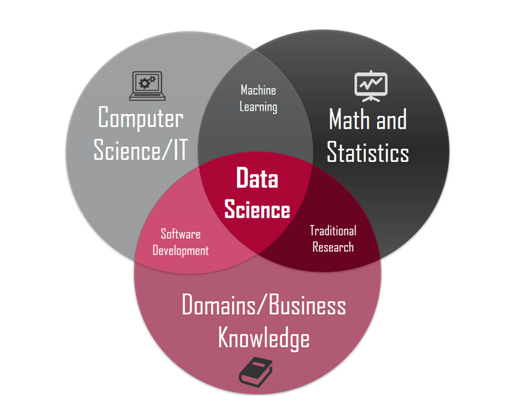
Com a crescente quantidade e diversidade de dados coletados em muitas áreas (graças a um mundo cada vez mais “informatizado”), uma possibilidade é fazer uso dessa informação como ponto de partida para elaborar novos conhecimentos. Nesse ponto que entra o machine learning, que é uma das áreas da inteligência artificial.
Inteligência Artificial
O aprendizado permite fazer novas predições a partir de experiências obtidas – ou seja, através da interação com seu meio. O cérebro do ser humano costuma avaliar situações de modo a minimizar riscos. Esse comportamento serve de analogia para as máquinas, que funcionariam de modo mais matemático e estatístico que o cérebro humano. Elas avaliam dados históricos para inferir uma lei geral (chamada de modelo matemático e formada por equações, com variáveis e coeficientes), com fins de prever novos valores.
A Inteligência artificial (AI, do inglês “artificial intelligence”) é o estudo e projeto de sistemas que percebem seu ambiente e tomam atitudes que maximizam suas chances de sucesso. Ela busca métodos ou dispositivos computacionais que possuam ou multipliquem a capacidade racional do ser humano de resolver problemas, pensar ou, de forma ampla, ser inteligente.
Segundo a hipótese da singularidade tecnológica, a “reação desenfreada” de um agente inteligente atualizável com capacidade de auto-aperfeiçoamento (como um computador que executa inteligência artificial baseada em software) geraria cada vez mais rapidamente, indivíduos dotados de uma super inteligência poderosa que, qualitativamente, ultrapassaria toda a inteligência humana.
Para os computadores possuírem consciência (conhecimento de sua própria existência), acredita-se que deveriam formá-la por si mesmos a partir de suas interações com o meio, e não serem programadas para isso. As máquinas teriam reações heurísticas (baseadas em processos cognitivos empregados em decisões não racionais) em vez da lógica racional. Heurística é o método de investigação com base na aproximação progressiva de um problema, de modo que cada etapa é considerada provisória.
Uma das formas para se diferenciar se essa singularidade foi ultrapassada é através do Teste de Turing. Ele serve para verificar a capacidade de uma máquina exibir comportamento inteligente equivalente (ou indistinguível) a um ser humano. O artigo da Wikipedia sobre Teste de Turing fala bastante sobre o assunto.
Existe a inteligência artificial fraca, na qual o objetivo é executar muito bem uma única função, e a forte, que combina um conjunto de tarefas executadas por um ser humano. O raciocínio de uma inteligência artificial pode ser realizado de dois modos: o indutivo, que extrai regras e padrões de grandes conjuntos de dados, e o dedutivo, que deduz comportamentos específicos a partir de proposições gerais.
Machine learning
O “machine learning” (ou aprendizado de máquina/automática/computacional) é o campo de estudo que dá aos computadores a habilidade de aprender sem serem explicitamente programados. Um algoritmo tradicional de programação recebe instruções lógica explícitas. Já no machine learning, o algoritmo de treinamento é condicionado para uma tarefa específica a partir de um (ou mais) conjunto(s) de dados.
Basicamente, a ideia principal é que ocorra um ganho de informação quando se vai de um estado A para um estado B. Quanto maior o ganho de informação, menor a entropia. Entropia é um termo geralmente associado ao que se denomina por “desordem”, o que em estatística muitas vezes é calculado pela incerteza. É assim que o algoritmo define qual o melhor caminho para continuar seguindo.
Em aprendizagem supervisionada, é dado um conjunto de amostras rotuladas de alguma forma útil em diferentes características. Então, alguma dessas três amplas categorias de tarefas podem ser utilizadas, conforme a natureza do “sinal” e “feedback” de aprendizado:
- Aprendizagem supervisionada: exemplos de inputs e outputs desejados são apresentados ao computador por um “professor” e o objetivo é aprender uma regra geral que mapeia os inputs aos outputs (a regressão matemática é um exemplo, mas com output contínuo)
- Aprendizagem não supervisionada: nenhum tipo de etiqueta dos dados é apresentado ao algoritmo de aprendizado, deixando-o sozinho para encontrar estrutura em seus inputs – são feitos agrupamentos automáticos de dados segundo seu grau de semelhança; a análise de cluster (“clustering”, ou agrupamento) é um exemplo desse tipo de aprendizado
- Aprendizagem por reforço: o programa interage com um ambiente dinâmico no qual ele deve desempenhar um determinado objetivo (dirigir um veículo ou aprender um novo jogo já jogando, por exemplo), sem um “professor” lhe dizer explicitamente se ele chega perto de seu objetivo ou não
Na verdade, é escolhida uma amostra dos dados e calculado o erro entre o valor obtido pela função calculada e os dados observados: se o erro estiver maior que um limite pré-estabelecido, a função deve ser refeita e o valor recalculado; caso contrário, o procedimento é finalizado. Esses passos são realizados várias vezes (o que é chamado de iteração), de modo a refinar o resultado para que ele seja cada vez melhor. Em cada passo, é atualiza a tabela de pesos, relacionados a cada etapa.
Por isso, é separado inicialmente uma amostra (geralmente 70% dos dados), para depois o algoritmo tentar prever os dados que não foram usados e que correspondem aos 30% restantes. Os dados previstos e a mostra de 30% são comparados pelo programador, simulando uma ação futura de trabalhar com novos dados.

Quando o modelo estatístico se ajusta em demasiado ao conjunto de dados/amostra, isso é chamado overfiting. Nesse caso, ele apresenta alta precisão quando testado com seu conjunto de dados, porém tal modelo não é uma boa representação da realidade (novos dados) – pode-se dizer que o modelo decora padrões em vez de aprender. O contrário é chamado de underfiting: o modelo é muito simples em relação aos dados que está tentando modelar e acaba subestimando a realidade.
Existem algumas finalidades do machine learning, como reconhecimento binário (se alguma coisa é ou não é), detecção de anomalias (fraudes em sistemas), previsão de valores, classificar amostras, etc. É comum usar técnicas de machine learning se o volume de dados utilizados é muito grande (muitas vezes da ordem de terabytes de dados).
Big Data é uma forma de armazenar, acessar e manipular um grande volume de dados, estejam estruturados (como em um banco de dados) ou não (como em e-mails). Uma boa parte de projetos de Machine Learning não usa Big Data, mas o inverso costuma ser verdadeiro.
A Rede Neural Artificial (RNA) é um tipo de machine learning, que também pode ser entendida como uma analogia ao cérebro humano. Ela é formada por nós chamados de neurônios, com uma função de entrada (função soma) e uma função de saída (função de transferência) cada. Eles são associados em uma ou duas camadas, onde cada uma tem um propósito. Por exemplo a identificação de imagens, a primeira camada reconhece contornos, a segunda identifica cor, etc.
O “deep learning” é uma rede neural que tem mais de 2 camadas e um maior número de recorrências. Nem sempre aumentar o número de camadas faz um resultado ficar melhor. Tem algoritmos que não dá pra ver o que acontece exatamente (só entende-se a lógica).
No cérebro, a sinapse é que contém o conhecimento, enquanto que o neurônio só avalia, e isso é análogo às RNAs. A própria rede aprende as característica que devem ser consideradas. Veja mais informações no post Redes Neurais Artificiais.
As árvores de decisão (“random forest“) são um método de aprendizado para classificação, regressão e outras tarefas que operam construindo uma multiplicidade de árvores de decisão no momento do treinamento e gerando a classe (se estiver trabalhando com classificação) ou predição de média. Ele cria perguntas que tenham sim ou não como resposta e o algoritmo deve descobrir as perguntas que melhor separam os resultados – como no jogo cara a cara, que um jogador pergunta ao outro se tem óculos, se tem cabelo loiro, e outras perguntas para eliminar resultados.
O Q-learning (“Q” de qualidade) é uma técnica usada em machine learning que atua como um reforço do aprendizado. Esse aprendizado por reforço envolve um agente, um conjunto de estados S e um conjunto de ações por estado A. Executando uma ação a (que pertence ao conjunto A), o agente muda de estado para estado. Executar uma ação em um estado específico fornece ao agente uma recompensa (pontuação numérica). O objetivo do agente é maximizar sua recompensa total (futura). Isso é feito aprendendo qual ação é ideal para cada estado. A ação ideal para cada estado é a ação que tem a maior recompensa a longo prazo. Essa recompensa é uma soma ponderada dos valores esperados das recompensas de todas as etapas futuras, a partir do estado atual.
Conceitos mais específicos
Os sistemas de machine learning aprendem como combinar dados de entrada para produzir previsões úteis sobre dados nunca antes vistos. Um modelo de regressão prevê valores contínuos, enquanto que um modelo de classificação prediz valores discretos.
Um problema pode ser trabalhado com técnicas de machine learning quando existe um padrão e não é fácil defini-lo matematicamente. Fazendo uma analogia com estatística, é preciso usar um conjunto de observações (amostras geradas por uma distribuição) para descobrir um processo subjacente (distribuição de probabilidades). Os dados são selecionados, é aplicado o algoritmo de aprendizagem e há algo que pode explicitamente detectar que dirá se aprendeu ou não (deve-se descobrir padrão, e não memorizar, pois se vierem dados novos, ele deve ser capaz de prever o comportamento).
Existem três princípios no machine learning:
- Navalha de Occam: o modelo mais simples que se ajusta aos dados também é o mais plausível;
- Viés de amostragem: se os dados são amostrados de forma tendenciosa, então a aprendizagem também produzirá um resultado tendencioso;
- Bisbilhotagem de dados: se um conjunto de dados afetou qualquer etapa do processo de aprendizado, então a capacidade do mesmo conjunto de dados avaliar o resultado foi comprometida (se usar propriedades adequadas do conjunto de dados, pode assumir relações antes de começar a escolha de modelos).
A Teoria Vapnik–Chervonenkis (VC) tenta explicar o processo de aprendizagem de um ponto de vista estatístico. A dimensão VC é uma medida da complexidade de um espaço de funções que pode ser aprendido por um algoritmo de classificação estatística, sendo definido como a cardinalidade do maior conjunto de pontos que o algoritmo pode quebrar. Se tiver poucos dados, modelo mais simples funciona melhor e complexo é um desastre; se tiver muitos dados, modelo simples pode melhorar pouco, mas complexo melhora bem mais.
A função alvo é uma função com um domínio X (do conjunto dos dados de entrada, com dimensão d) e contra-domínio Y (conjunto das saídas). Hipótese é o nome formal para chamar a fórmula (função g) obtida para aproximar a função alvo (f). O modelo vai trabalhar com várias hipóteses, das quais uma será escolhida como a melhor (com menor erro). O bias (viés) é diferença ao quadrado da melhor função (g) e função alvo (f) – aprendendo ou não, o conjunto de hipóteses é tendencioso com relação à função alvo.
A desigualdade de Hoeffding fornece um limite superior na probabilidade de que a soma de variáveis aleatórias independentes limitadas se desvie de seu valor esperado em mais do que uma certa quantia. Quando generalizada, modelos muito sofisticados (com grande número de hipóteses) fazem perder a ligação entre uma amostra e o total de amostras, o que implica em decorar para uma amostra em vez de fazer um aprendizado que possa ser generalizado para o conjunto todo.
Um “label” (ou rótulo) é a variável que estamos prevendo, enquanto que uma “feature” (atributo) é a variável de entrada, podendo ser mais de uma. Fazendo uma analogia com uma regressão linear simples (y = ax + b), o ‘y’ seria o label, o ‘x’ seria a feature, o ‘b’ seria o bias (viés, onde corta o eixo y) e ‘a’ seria o peso (“weight“). Para cada feature, existe um peso associado.
Treinar (“training“) um modelo significa simplesmente aprender (determinar) bons valores para todos os pesos e o viés de exemplos rotulados. Na aprendizagem supervisionada, um algoritmo de aprendizado de máquina constrói um modelo examinando muitos exemplos e tentando encontrar um modelo que minimize a perda. Uma parte dos dados aleatória dos dados deve ser separada para treinamento e outra para validação. Ainda é costume separar um conjunto de teste para estimar o erro de predição do modelo escolhido e ter certeza de que o modelo não está superajustado. Normalmente, essa divisão dos dados é feita usando três conjuntos distintos:
- Conjunto de Treinamento – usado para treinar o modelo (o modelo vê e aprende com os dados). Os pesos do modelo são atualizados com base nos dados deste conjunto;
- Conjunto de Validação – usado para ajustar os hiperparâmetros do modelo, como a taxa de aprendizado, o número de épocas e assim por diante. Ele permite que você faça ajustes no treinamento sem olhar para os dados de teste. A validação também ajuda a monitorar o desempenho do modelo durante o treinamento e ajustar estratégias para melhorar o desempenho;
- Conjunto de Teste – usado para avaliar o desempenho final do modelo após o treinamento. Ele fornece uma estimativa imparcial da capacidade do modelo de generalizar para novos dados.
É uma prática comum usar a divisão padrão, como 70% para treinamento, 15% para validação e 15% para teste, ou variações disso. No entanto, a divisão exata pode variar dependendo do tamanho do conjunto de dados, da natureza do problema e da disponibilidade de dados.
Caso o volume de dados seja pequeno, uma alternativa é a validação cruzada, ou “cross validation“. Nela, são selecionados diferentes conjuntos de dados (“kfolders”) que são seleções diferentes do conjunto total de dados. Por exemplo, são selecionados 1/10 dos dados para validação e o restante para treinamento; depois, outro conjunto de 1/10 para validação (pode ser uma outra amostra randômica ou um conjunto de dados diferentes) e assim por diante. O resultado (e o erro) é a média dos resultados (e erros) de todas as validações (sessões de treinamento) contendo N-K amostras, sempre variando os conjuntos de amostras: K = N/10.
A perda (“loss“) é a penalidade por uma má previsão em um único exemplo, que pode ser quantificada por métricas como o “Mean square error (MSE)”. Esse é um cálculo que é conhecido como função de perda (“loss function”): uma medida de quão bom um modelo de previsão faz em termos de ser capaz de prever o resultado esperado.
O algoritmo do gradiente descendente (“Gradient Descent” – SGD) calcula o gradiente da curva de perda (inclinação) e indica qual o caminho para minimizar o erro (vale de um gráfico da perda em função do peso), redefinindo o peso – quando há vários pesos, o gradiente é um vetor de derivadas parciais com relação aos pesos. Esse vetor gradiente (com direção e magnitude) é multiplicado por um escalar conhecido como taxa de aprendizado (“learning rate” ou “step size”) para determinar o próximo ponto. A heurística de buscar mínimo local começa de diferentes valores para então encontrar o melhor dentre todos. A aleatoriedade permite encontrar outros mínimos locais, e então depois dá pra escolher o melhor, que pode ser o mínimo global.
Uma taxa de aprendizado pequena demais faz o aprendizado mais demorado, mas se for grande demais, pode nunca encontrar o melhor peso referente ao menor erro. De modo geral, um início com learning rate = 0.1 é um bom começo e a melhor variação de taxa em função das rodadas é aquela que não é constante, ou seja, conforme vai avançando, vai diminuindo para não passar do ponto (nem demorar muito pra chegar nele).
Cada etapa (“step“) é o número total de iterações de treinamento. Uma etapa calcula a perda de um lote e usa esse valor para modificar os pesos do modelo uma vez. O tamanho do lote (“batch size“) é o número total de exemplos (escolhidos aleatoriamente) usados para calcular o gradiente em uma única etapa (conjunto de dados inteiro). O número total de exemplos treinados é o produto entre o “bacth size” e o “steps”. Tamanhos de lote muito pequenos podem causar instabilidade – primeiro tente valores maiores, como 100 ou 1000, e diminua até ver degradação.
Cada ciclo completo de treinamento é chamado de época (“epoch“). Um gráfico de erro/perda em função de épocas indica como o treinamento está evoluindo. Em cada epoch, podem existir resultados piores, mas o melhor é guardado e exibido sempre, a não ser que surja um melhor (procedimento conhecido como “pocket algorithm”). O erro de treinamento deve diminuir constantemente, de forma abrupta no início, e eventualmente estabilizar conforme o treinamento converge. Se o treinamento não convergiu, tente executá-lo por mais tempo. Se o erro de treinamento diminuir muito lentamente, o aumento da taxa de aprendizado pode ajudar a diminuir mais rapidamente – mas, às vezes, o oposto pode acontecer se a taxa de aprendizado for muito alta. Se o erro de treinamento variar muito, tente diminuir a taxa de aprendizado – menor taxa de aprendizado e um número maior de etapas ou um tamanho de lote maior geralmente é uma boa combinação.
Esse gráfico de perda em função de épocas também pode ser construído para o conjunto de dados de teste. Se a curva de perda em função de épocas cair muito para o treinamento e não acontecer o mesmo com os dados de teste, isso revela que o modelo está treinado em excesso para as amostras de treino e não consegue prever usando um novo conjunto de amostras.
Esse fenômeno é conhecido como “overfitting“, acontecendo quando o ruído é ajustado também, só que o ruído não tem padrão a ser descoberto. O ruído pode ser estocástico/aleatório ou determinístico, relacionado a informação que existe mas os dados (ou o conjunto de hipóteses) não conseguem promover o aprendizado dessa informação (como se fosse explicar números complexos para uma criança: no máximo, podem criar um padrão que não existe), sendo uma consequência da limitação do modelo. Mais pontos leva a uma menor chance de “overfitting”. Se o erro de um modelo mais complexo for maior que o de um modelo menos complexo, tem “overfitting” quanto maior for a diferença positiva do mais complexo pelo menos.
O decaimento de peso (“weight decay”) é uma constante lambda regularizadora, que restringe os pesos na direção da função alvo e melhora ajuste (reduz “overfitting”). Ele deve punir mais o ruído do que o sinal (hipóteses devem ser mais suaves, pois ruído estocástico tende a ter alta frequência). Pesos pequenos deixam modelo mais próximo do linear (mesmo com muitos neurônios e camadas), enquanto pesos maiores vão para modelos não-lineares.
Normalizar (“normalizing“) significa converter valores de recurso de ponto flutuante de seu intervalo natural (por exemplo, 100 a 900) em um intervalo padrão (por exemplo, 0 para 1 ou -1 para +1). Um exemplo desse tipo de cálculo é: (valor – mínimo)/(máximo – mínimo). Se o conjunto de dados é composto de múltiplos “features”, a normalização gera benefícios, como ajudar a descida gradiente a convergir mais rapidamente, evitar que um número torne-se NaN por exceder seu limite de precisão e ajudar o modelo a aprender os pesos apropriados para cada “feature”. A normalização deve ocorrer depois de separar os dados de treinamento e de teste.
A padronização (“standardizing“) é um cálculo importante para comparar medidas com diferentes unidades. Um exemplo desse tipo de cálculo é o “Z score”: (valor – média) / (desvio padrão). A padronização deve ser feita antes da normalização.
Um modelo linear pode ser composto de mais de um “input” na camada de entrada e um “output” na camada de saída. Já um modelo que precisa descrever fenômenos não-lineares (não é possível definir uma linha reta para separar dois conjuntos de dados), deve incluir uma combinação de camadas ocultas (“hidden layers“) entre a entrada e a saída (para introduzir um elemento não-linear e não ser apenas uma soma linear dos inputs e pesos). Geralmente, são usadas 2 a 3 camadas ocultas.
Uma fórmula para descobrir o número total de camadas ocultas necessárias e outras dicas estão no post do Stackoverflow – How to create a neural network with regression model? Ao final da série de treinamentos, escolha o modelo que faz melhor no conjunto de validação e verifique novamente esse modelo em relação ao conjunto de testes. As previsões de regressão logística não devem apresentar viés (“bias”), ou seja, a média de previsões deve ser aproximadamente a média das observações.
O curso Introduction to Machine Learning do Google tem um “playground exercise” que permite avaliar o impacto desses parâmetros na evolução de um conjunto de dados e diferentes configurações de redes neurais.
Outra boa fonte de estudos é o curso de Machine Learning do Caltech, com 18 aulas de 1h cada (mais perguntas) do Professor Yaser Abu-Mostafa. Elas intercalam conteúdo teórico (definições matemáticas), técnico (com aspectos práticos, mas sem programação) e de análises conceituais.
Por fim, há também o curso do MIT de Inteligência Artificial e o Programa de cursos integrados Machine Learning with TensorFlow on Google Cloud Platform do Coursera.



One comment