O disco rígido do computador possui boa parte de seu mecanismo baseado em peças mecânicas, necessitando de maior manutenção. A grande maioria dos HDs é preparada para trabalhar pesado por mais de três anos, portanto seu uso massivo não é o grande problema, e sim a falta de manutenção por parte do usuários. Alguns HDs começam a apresentar falhas de leitura, gravação e até fazem cliques quando estão “morrendo” (clique no link para ver e ouvir) – mas seria engraçado se fizesse esse som junto com os drives de disquete (banda “Hard Disk and the floppys drives”):
Uma tecnologia cada vez mais presentes nos HDs é a S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology), um sistema de monitoramento de discos rígidos que detecta e antecipa falhas, através de vários indicadores de confiabilidade. No Linux, você pode utilizar a ferramenta “smartmontools”, que pode ser instalada diretamente do repositório (“sudo apt install smartmontools”). Ela vem com dois programas: smartctl (de uso interativo) e smartd (monitoramento contínuo).
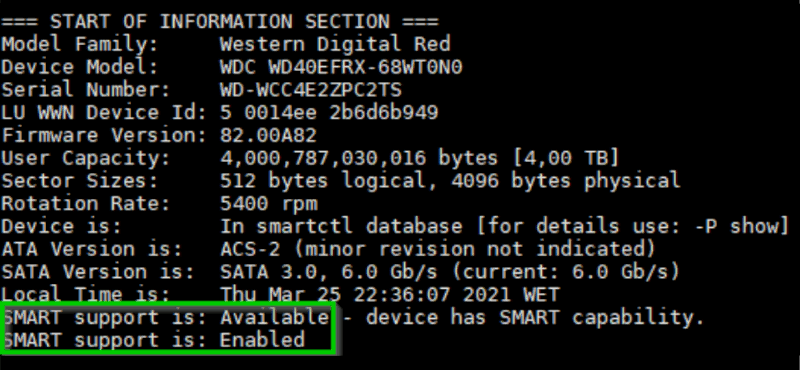
Para checar se o HD tem o SMART, primeiro deve descobrir o diretório “/dev” que aponta para o dispositivo. Digite o comando “smartctl –scan” para ver os dispositivos que existem. Depois, execute o seguinte comando (trocando o DEVICE_NAME pelo dispositivo a ser testado, sda, sdc… por exemplo):
sudo smartctl -i /dev/DEVICE_NAME
Dentre várias informações, se o HD tiver o SMART, aparecerá no final:
SMART support is: Available - device has SMART capability. SMART support is: Enabled
Para o smartctl acessar o drive, use o seguinte comando:
sudo smartctl -s on -o on -S on /dev/DEVICE_NAME
onde “-s on” liga o SMART se não estiver “enable”, “-o on” desliga o “data collection” e “-S on” liga o “autosave of device vendor-specific Attributes”. O comando deve retornar:
=== START OF ENABLE/DISABLE COMMANDS SECTION === SMART Enabled. SMART Attribute Autosave Enabled. SMART Automatic Offline Testing Enabled every four hours.
Para checar a saúde como um todo, use:
sudo smartctl -H /dev/DEVICE_NAME
Deverá retornar o seguinte (se não retornar, faça o backup AGORA):
=== START OF READ SMART DATA SECTION === SMART overall-health self-assessment test result: PASSED
Passando do teste inicial, existem três tipo de teste que podem ser feitos no dispositivo: Short (roda testes que tem maior probabilidade de encontrar problemas, demora poucos minutos), Extended (ou Long; checagem completa do disco, demora horas) e Conveyance (identifica se houve danos durante transporte do dispositivo). Para estimar o tempo que os testes “short” e “extended” levarão, execute a primeira linha; para o teste curto, a segunda linha; e para o teste completo, a última linha:
sudo smartctl -c /dev/DEVICE_NAME sudo smartctl -t short /dev/DEVICE_NAME sudo smartctl -t long /dev/DEVICE_NAME
Para checar os resultados ou andamento de qualquer comando acima, execute o comando da primeira linha abaixo:
sudo smartctl -l selftest /dev/DEVICE_NAME sudo smartctl -A /dev/DEVICE_NAME
Cada um dos atributos SMART possui várias colunas, conforme mostrado pelo segundo comando:
- ID: número do atributo (lista completa na Wikipedia).
- ATTRIBUTE_NAME: nome do atributo SMART.
- Valor: valor normalizado atual do atributo; valores mais altos são sempre melhores (exceto a temperatura dos discos rígidos de alguns fabricantes). O intervalo é normalmente 0-100, para alguns atributos 0-255 (de modo que 100 e 255 é o melhor, 0 é o pior).
- WORST: pior valor (normalizado) que esse atributo teve.
- THRESH: limite abaixo do qual o valor normalizado será considerado “excedendo as especificações” e muda a coluna “TYPE”.
- TYPE: tipo do atributo. “Pre-fail” indica que está no período “antes da falha” e “Old_age” apenas indica desgaste.
- WHEN_FAILED: em um HD saudável, esta coluna fica limpa para todas as opções, indicando que o HD nunca apresentou os erros.
Deve-se permanecer atento quando uma unidade que começa a obter setores defeituosos (ID 5) ou setores pendentes (ID 197) geralmente será descartada em 6 meses ou menos. A única exceção seria se isso não acontecesse: ou seja, a contagem de setores inválidos aumenta, mas fica estável por um longo período, como um ano ou mais. Por esse motivo, normalmente é necessária uma ferramenta de diagramação / registro no diário para o SMART.
De acordo com o documento do Google Labs, Failure Trends in a Large Disk Drive Population, “após o primeiro erro de verificação [qualquer tipo de erro de setor incorreto, causado por instabilidade de leitura ou danos à mídia], os drives têm 39 vezes mais probabilidade de falhar dentro de 60 dias do que os drives sem esses erros. Os primeiros erros nas realocações, realocações off-line e contagens probatórias também estão fortemente correlacionados a probabilidades de falha mais altas. Apesar dessas fortes correlações, constatamos que os modelos de previsão de falha baseados apenas nos parâmetros SMART são limitados em sua precisão de previsão, uma vez que uma grande fração de nossos drives com falhas não demonstrou nenhum sinal de erro SMART.”
Para facilitar um pouco o trabalho, o script abaixo faz as verificações necessárias. Copiei, salve como um arquivo “smartctl_easy.sh” e transforme-o em um executável (chmod +x smartctl_easy.sh). Ao executá-lo, será exibido o horário previsto de término do teste (curto ou longo), para então usar o comando de verificação do resultado (sudo smartctl -l selftest /dev/
#!/bin/bash # Script para fazer checagem de disco # Escolha o dispositivo dev_name='sdc' # Teste curto ou longo? test_type='short' #test_type='long' sudo smartctl -i /dev/$dev_name sudo smartctl -H /dev/$dev_name sudo smartctl -t $test_type /dev/$dev_name # Para verificar resultado, executar após o tempo informado pelo último comando #sudo smartctl -l selftest /dev/$dev_name
Para ver um script que ajuda no monitoramento da saúde do HD e outros aspectos importantes de hardware um ou mais computadores, veja o post Monitorar status de computadores.
Configurando o smartd – verificação rotineira automática
Em vez de repetir a seção anterior diariamente, é possível configurar o smartd para fazer tudo automaticamente. Ele fica responsável por executar o teste conforme agendamento próprio e salvar os resultados no log do sistema, que você pode acompanhar usando o comando “cat /var/log/syslog | grep smartd” ou “smartctl -l selftest /dev/”.
Caso o computador tenha o arquivo “/etc/default/smartmontools”, descomente a linha contendo “start_smartd=yes”. O padrão do serviço é monitorar todos os HDs disponíveis, mas isso pode ser configurado no arquivo “/etc/smartd.conf”. Um exemplo de configuração desse arquivo:
1) Comentar a única linha descomentada por padrão, que começa com “DEVICESCAN”
2) Adicione a seguinte linha, cujos parâmetros podem ser opcionais em alguns casos:
/dev/sda -a -d sat -o on -S on -s (S/../.././02|L/../../6/03) -m root -M exec /usr/share/smartmontools/smartd-runner
Substitua “/dev/sda” pelo dispositivo que deseja monitorar (ou use DEVICESCAN para realizar o monitoramento em todos os dispositivos do computador). O parâmetro “-a” habilita algumas opções comumente utilizadas, “-d sat” força identificar o dispositivo como SATA (só usar no caso de não reconhecer), “-m root” manda e-mail além de gravar as saídas no log de sistema e “-M exec /usr/share/smartmontools/smartd-runner” é usado em distribuições Debian e Ubuntu.
As opções de agendamento são feitas através do parâmetro “-s”. Os campos são: tipo de teste (S ou L), mês (dois dígitos ou dois pontos para todos os meses), dia do mês (no mesmo esquema), dia da semana (onde 1 é segunda-feira e ponto é para todos os dias da semana) e hora de início (dois dígitos, indicando que começa em algum horário entre 1 e 2 da manhã). Para mais de um scan, separar por pipe cada grupo. No exemplo, estão programados um teste curto para ser executado diariamente às 2:00 da manhã e um teste longo no sábado às 3:00 da manhã.
Depois de alterar esse arquivo é preciso reiniciar o serviço através do seguinte comando “sudo /etc/init.d/smartmontools restart”. Mais informações em Monitoring Hard Drive Health on Linux with smartmontools e Monitorando a saúde do HD com o SMART, além do comando “man smartd.conf”.
Disco com erros de leitura
Ao checar os resultados, será exibida uma lista com o teste mais recente realizado no topo. No caso de erro (status como “Completed: read failure”), aparecerá o LBA_of_first_error (Logical Block Address do primeiro erro) correspondente. Pegue esse número e multiplique por (512/4096), ou seja, divida por 8. Então, grave zero nessa posição através do seguinte comando:
dd if=/dev/zero of=/dev/sda conv=sync bs=4096 count=1 seek=LBA_dividido_por_8
Então refaça o teste rápido e veja se o erro foi eliminado. Caso apareça um novo setor defeituoso, repita o procedimento para o novo setor. Veja esse script para “facilitar” esse processo:
#!/bin/bash
# Script para gravar zero em setores defeituosos
dispositivo='sdb'
# Gravar arquivo com resultados do último teste de disco (somente linhas com mensagens)
smartctl -l selftest /dev/$dispositivo | grep "#" > erros.txt
# Gravar em array "setores" somente os "LBA_of_first_error"
mapfile -t setores < <(cat erros.txt | sed 's/^.....//' | awk '{ print $8 }')
# Para cada endereço, calcular posição correspondente e gravar zero
for (( i=0; i<${#setores[@]}; i++ )); do
LBA=${setores[i]}
setor=$((LBA/8))
setor_antes=$((setor-1))
setor_depois=$((setor+1))
echo "Curando setor" $setor
dd if=/dev/zero of=/dev/$dispositivo conv=sync bs=4096 count=1 seek=$setor
dd if=/dev/zero of=/dev/$dispositivo conv=sync bs=4096 count=1 seek=$setor_antes
dd if=/dev/zero of=/dev/$dispositivo conv=sync bs=4096 count=1 seek=$setor_depois
done
# Executar teste novamente para ver novo estado do disco
smartctl -t short /dev/$dispositivo
O número de setores defeituosos no drive (não remapeados) pode ser visto nos atributos “197 Current_Pending_Sector” e “198 Offline_Uncorrectable”, onde o número de bad blocks é informado na última coluna. Em casos extremos, onde existam vários badblocks não marcados, você pode usar o truque de encher o HD com zeros, usando o comando “dd if=/dev/zero of=/dev/hda” para forçar a controladora a escrever em todos os blocos e assim remapear os setores (perdendo todos os dados, naturalmente). O número de setores defeituosos já remapeados pode ser acompanhado através dos atributos “5 Reallocated_Sector_Ct” e “196 Reallocated_Event_Count”.
Uma outra forma de verificar os blocos com problemas é o programa badblocks, usado para buscar bad blocks no dispositivo. Veja esse exemplo, que investiga o dispositivo “sdb” e grava os bad blocks encontrados em um arquivo:
sudo badblocks -o badblocks_encontrados.dat -svn /dev/sdb
A opção “-n” realiza um teste não destrutivo, mantendo os dados originais, enquanto que “-w” destrói os dados (mas demora menos). Também é realizado um remapeamento dos bad blocks. Esse programa é ativado quando se usa a opção “-c” no programa e2fsck (se colocar o c duas vezes, é realizado um teste não destrutivo).
HDs em RAID
Caso os HDs estejam em um array, deverá ser acrescentada a opção “-d megaraid,N”, onde N é o “device number” do HD a ser testado. Para descobrir esse número, utilize o comando a seguir, que permite saber as informações do HD, variando o valor de N (lembrando que é o dispositivo, obtido através do comando “fdisk -l”) . Busque o HD pelo seu “serial number”.
sudo smartctl -a -d megaraid,N /dev/sd<device>
Para verificar o status do array, utilize o comando “megactl” (discos SCSI, etc) e “megasasctl” (discos SAS). Drivers recentes megaraid podem exigir dispositivos sg ou BSD para acessar unidades físicas. Nesse caso, use ” lsscsi -gs ” para detectar o dipositivo “/dev/sgX” apropriado (instalado através do comando “apt-get install lsscsi” – veja mais no post Use smartctl To Check Disk Behind Adaptec RAID Controllers. Para ver mais sobre Smartmontools e correção de setores ilegíveis de disco, clique no link.
Uma alternativa é a SeaTools para DOS (clique no link para um tutorial de uso). Você deverá gravar um CD com a imagem disponível no site e dar o boot com ele, e aí realizar os testes.
Verificando a consistência do sistema de arquivos
Em casos de queda de energia, desligamento incorreto do computador (sem ser via halt ou shutdown) ou defeitos físicos no disco rígido, pode acontecer de corromper arquivos no sistema. A ferramenta “smartmontools” permite checar a existência de “bad blocks” e outros problemas físicos. Já a ferramenta “fsck” (de “file system consistency check”) é usada para verificar a consistência/integridade de um sistema de arquivos no Unix buscando erros lógicos. Em caso de falhas, o sistema automaticamente faz a leitura dos logs ou journal e compara com o estado atual. Se houverem inconsistências entre os logs e o sistema atual, o Linux tenta fazer a correção automaticamente. Mas se isso não for possível, deve-se efetuar uma verificação manual para a correção do problema através da FSCK. Veja mais no post Erro ao inicializar o Linux – Give root password for maintenance.

6 comments